
티스토리 뷰
불균형 데이터 다루기 - Resampling
Kaggle - Resampling strategies for imbalanced datasets 을 중심으로 정리한 글입니다.

Classification에서 불균형 데이터를 다루는 방법을 resampling 에 중점을 두고 under-sampling, over-sampling의 대표적인 것들을 알아보자.
불균형 데이터셋이 뭔데?
불균형 데이터셋은 각 클래스가 가지고 있는 데이터양 차이가 커서 불균형한 데이터셋을 말한다. 대표적인 불균형 데이터셋은 다음과 같다.
금융사기: 금융사기 데이터셋은 실제 사기 데이터가 1~2%밖에 되지 않는다.광고 클릭 예측: 클릭 예측 데이터 세트도 클릭률이 그렇게 높지가 않다.항공 사고: 비행기 사고가 발생하는 경우가 별로 없다.암 진단: 환자가 암을 가지고 있는 경우가 드물다.
위와 같은 불균형 데이터셋을 그대로 학습시키면 모델의 학습을 저해할 뿐만 아니라 실제로는 높은 정확도가 아님에도 높은 정확도로 우리를 현혹할 수도 있다.
Metric의 함정
불균형 데이터를 가지고 학습한 모델을 평소처럼 간단하게 측정하면 잘못된 결과에 빠질 수 있다. 심하게 불균형한 데이터셋을 학습한 모델은 피처 분석을 수행할 필요 없이 냅다 일반적인 클래스만 항상 예측할 수 있기 때문에 정확도가 괜찮게 나올 수 있다. 그렇기 때문에 불균형 데이터셋을 다룰 때는 모델의 평가지표를 신중하게 선택해야 한다. 여기서 그 방법은 자세히 다뤄보진 않을 것이나 원한다면 Confusion Matrix, ROC Curve 를 참고하자.
Resampling
불균형 데이터셋을 다루는 여러가지 방법이 있지만 가장 간단하고 많이 이용되는 기술이 바로 resampling이다. 이것은 under-sampling, over-sampling으로 이루어져있다.
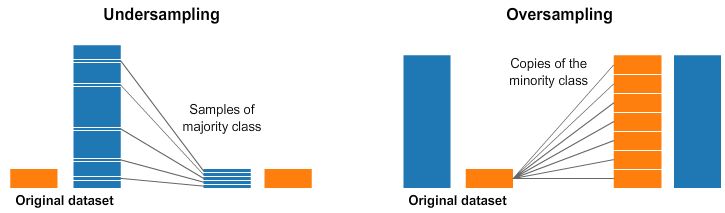
- under-sampling
- 다수 클래스에서 샘플을 삭제하는 것.
- 간단한 구현은 무작위 records를 삭제하는 것이다.
- 다수의 정보를 잃는다.
- over-sampling
- 소수클래스에 샘플을 추가하는 것
- 간단한 구현은 다수클래스에서 무작위 records를 복제하는 것이다.
- Overfitting 문제가 있다.
Random Over-sampling & Random Under-sampling
over-sampling과 under-sampling의 가장 간단한 구현은 무작위로 record들을 복제하고 삭제하는 것이다. 이는 간단하지만 over-sampling에서는 심하게 불균형한 데이터에서는 Overfitting문제가, under-sampling에서는 정보를 잃는 문제가 일어날 수 있다.
구현
sklearn을 이용하여 클래스 0을 다수클래스로 클래스 1을 소수클래스로 가지는 불균형 데이터셋을 생성해보자.
from sklearn.datasets import make_classification
X, y = make_classification(
n_classes=2, class_sep=1.5, weights=[0.9, 0.1],
n_informative=3, n_redundant=1, flip_y=0,
n_features=20, n_clusters_per_class=1,
n_samples=100, random_state=10
)
df = pd.DataFrame(X)
df['target'] = ynum_0 = len(X[X['target']==0])
num_1 = len(X[X['target']==1])
undersampled_data = pd.concat([ X[X['target']==0].sample(num_1) , X[X['target']==1] ])
oversampled_data = pd.concat([ X[X['target']==0] , X[X['target']==1].sample(num_0, replace=True) ])Python imbalanced-learn module
파이썬의 imbalanced-learn 을 이용하여 더 심플하게 구현할 수 있다.
먼저 make_classification으로 만들었던 정보를 재활용하겠다. 이것을 2D 공간으로 표현하면 다음과 같다.(다수의 피처, 즉, 차원들이 있지만 2D로 표현하고 싶으니까 PCA를 통하여 크기를 줄였다. 여기서는 PCA에 대하여 다루진 않겠다.)

클래스 0의 데이터가 많은 것을 볼 수 있다. imbalanced-learn 을 이용하여 under-sampling을 해보자.
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler()
X_rus, y_rus = rus.fit_resample(X, y)
print('Removed Indexes:', rus.sample_indices_)Removed Indexes: [96 12 98 39 64 83 90 47 20 35 4 8 9 14 16 40 67 70 71 74]
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler()
X_ros, y_ros = ros.fit_resample(X, y)
print(X_ros.shape[0] - X.shape[0], 'new random picked points')
80 new random picked points
그래프상에서는 별반 다를 것이 없어 보이지만 새로운 resample shape와 기존의 shape를 비교해보면 80개의 무작위 포인트가 선택된 것을 볼 수 있다.
하지만 이렇게 단순히 삭제하고 복제하는 방식은 모델의 학습에 해로운 영향을 끼쳤고 그렇기 때문에 보다 더 정교한 기법이 제안되어왔다. 예를 들면 clustering 을 이용하는 것이다. 무리를 짓는다는 뜻인 clustering은 이름 그대로 클래스의 record들을 클러스터링해서 좀 더 효율적인 under-sampling과 over-sampling이 가능하게 해준다. under-sampling에서
다수의 클래스 record들을 무리 짓고 각각의 무리에서 행을 제거함으로써 최대한 정보를 보존할 수 있고 over-sampling에서는 클래스 record들을 바로 복제하는 대신, 복제에 조금의 변형을 주어 더 다양한 복제 샘플을 만들 수 있는 것이다.
계속해서 imbalanced-learn 을 이용하여 몇 가지를 소개하고 구현해보겠다.
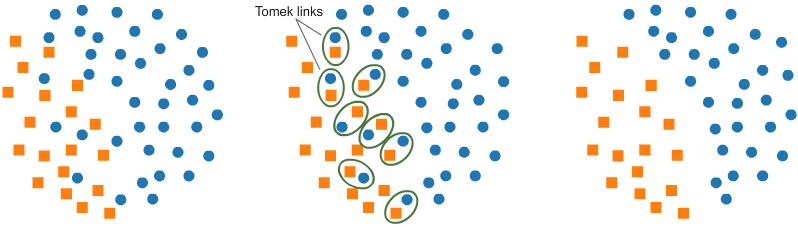
Under-sampling: Tomek links
이 논문이 나오기 전에는 제거하려는 다수 클래스에서 k-nearest neighbors에 있는 샘플만 무작위로 선택하여 제거했었다. 하지만 Tomek 이란 사람이 소수 클래스 데이터와 가장 낮은 유클리디안 거리를 갖는 다수 클래스를 삭제하여 두 클래스 사이의 공간을 늘렸고 분류 프로세스를 용이하게 했다. 가장 낮은 유클리디안 거리를 가져 인접한 인자의 한 쌍이지만 서로 다른 클래스들을 Tomek links 라고 부른다.
from imblearn.under_sampling import TomekLinks
tl = TomekLinks(sampling_strategy='majority')
X_tl, y_tl = tl.fit_resample(X, y)
print('Removed Indexes:', tl.sample_indices_)
Removed Indexes: [ 0 1 2 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
25 26 27 28 29 30 31 32 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49
50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73
74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 90 91 92 93 94 95 97 98 99]
Under-sampling: Cluster Centroids
이 기술은 클러스터링 방법을 기반으로 중심을 생성하여 under-sampling을 진행한다. 정보를 보존하기 위해서 이전의 유사성을 기준으로 그룹화한다.
from imblearn.under_sampling import ClusterCentroids
cc = ClusterCentroids(sampling_strategy={0: 10})
X_cc, y_cc = cc.fit_resample(X, y)
plot_2d_space(X_cc, y_cc, 'Cluster Centroids under-sampling')
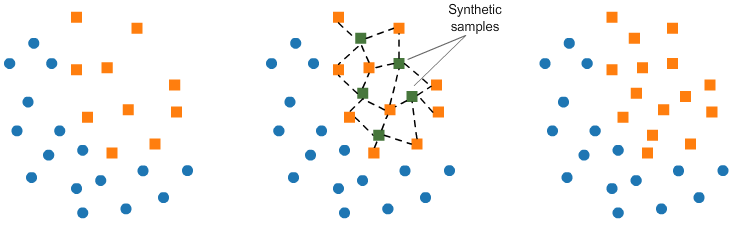
Over-sampling: SMOTE
over-sampling에서 가장 많이 쓰이는 기법인 SMOTE(Synthetic Minority Oversampling TEchnique)은 이미 존재하는 소수 클래스에 대한 합성 요소로 구성된다. SMOTE가 합성샘플을 만들어내는 방법은 다음과 같다.
- 소수 클래스에서 무작위로 k포인트를 선택
- 랜덤 데이터와 k개의 최근접 이웃 간의 유클리디안 거리를 계산 (k-nearest neighbors를 계산)
- 거리를 0과 1 사이의 랜덤한 수로 곱한 다음 합성 샘플로 소수 클래스에 결과를 추가.
- 합성 포인트는 선택한 포인트와 인접 포인트 사이에 추가.
- 소수클래스의 원하는 비율이 충족될 때까지 반복.
이 방법은 생성된 합성 데이터가 소수 클래스의 피처 공간과 비교적 가깝기 때문에 랜덤 오버샘플링과는 다르게 데이터에 새로운 '정보' 를 추가한다. 그렇기 때문에 더 효과적이다.
from imblearn.over_sampling import SMOTE
smote = SMOTE(sampling_strategy='minority')
X_sm, y_sm = smote.fit_resample(X, y)

Over-sampling followed by under-sampling
소수 클래스에 대한 합성 데이터를 생성하는 SMOTE와 다수 클래스에서 Tomek 링크로 식별되는 데이터를 제거하는 Tomek links를 결합해서 사용해보자.
from imblearn.combine import SMOTETomek
smt = SMOTETomek(sampling_strategy='auto')
X_smt, y_smt = smt.fit_resample(X, y)

참 고
https://www.kaggle.com/rafjaa/resampling-strategies-for-imbalanced-datasets
https://imbalanced-learn.org/stable/references/index.html#api
'ML' 카테고리의 다른 글
| 2. 미니배치 경사하강법 (Mini-batch Gradient Descent) (0) | 2023.07.24 |
|---|---|
| 1. 경사하강법과 역전파 정리 (0) | 2023.07.24 |
| 로지스틱 회귀와 신경망의 차이 (0) | 2021.08.15 |
| 역전파와 경사하강법의 차이점 (0) | 2021.08.14 |
| Logistic Regression (로지스틱 회귀) (0) | 2021.08.12 |